一、块存储
# 查看块设备映射信息 [root@client1 ~]# rbd showmapped id pool image snap device 0 rbd demo-image - /dev/rbd0 [root@client1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 253:0 0 30G 0 disk └─vda1 253:1 0 30G 0 part / rbd0 252:0 0 7G 0 disk /mnt # 停用设备 [root@client1 ~]# umount /mnt/ [root@client1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 253:0 0 30G 0 disk └─vda1 253:1 0 30G 0 part / rbd0 252:0 0 7G 0 disk # 已经卸载 [root@client1 ~]# rbd unmap /dev/rbd0 [root@client1 ~]# lsblk # /dev/rbd0消失 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 253:0 0 30G 0 disk └─vda1 253:1 0 30G 0 part /
二、快照
快照可以保存某一时间点时的状态数据
希望回到以前的一个状态,可以恢复快照
# 新建名为img1的镜像 [root@node1 ~]# rbd create img1 --size 10G [root@client1 ~]# rbd list # 查看镜像名 # 映射为本地硬盘 [root@client1 ~]# rbd map img1 /dev/rbd0 # 格式化后挂载 [root@client1 ~]# mkfs.ext4 /dev/rbd0 [root@client1 ~]# mount /dev/rbd0 /mnt [root@client ~]# cp /etc/hosts /mnt/ [root@client ~]# ls /mnt/ hosts lost+found # 查看img1的快照 [root@node1 ~]# rbd snap ls img1 # 为img1创建名为img1-snap1的快照。 [root@node1 ~]# rbd snap create img1 --snap img1-snap1 [root@node1 ~]# rbd snap ls img1 # 查看镜像的快照 SNAPID NAME SIZE 6 img1-snap1 10240 MB # 删除快照 [root@node1 ~]# rbd snap remove img1 --snap img1-snap1 # 删除镜像,删除前需要在客户端卸载它 [root@client1 ~]# umount /mnt [root@client1 ~]# rbd unmap /dev/rbd0 [root@node1 ~]# rbd rm img1
2.1使用镜像、快照综合示例
# 1. 在rbd存储池中创建10GB的镜像,名为img1 [root@node1 ~]# rbd --help # 查看子命令 [root@node1 ~]# rbd help create # 查看子命令create的帮助 [root@node1 ~]# rbd create img1 --size 10G [root@node1 ~]# rbd list img1 [root@node1 ~]# rbd info img1 rbd image 'img1': size 10240 MB in 2560 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.1061238e1f29 format: 2 features: layering flags: # 2. 在客户端使用镜像img1,将其挂载到/mnt [root@client1 ~]# rbd list img1 [root@client1 ~]# rbd map img1 /dev/rbd0 [root@client1 ~]# mkfs.xfs /dev/rbd0 [root@client1 ~]# mount /dev/rbd0 /mnt/ [root@client1 ~]# rbd showmapped id pool image snap device 0 rbd img1 - /dev/rbd0 [root@client1 ~]# df -h /mnt/ 文件系统 容量 已用 可用 已用% 挂载点 /dev/rbd0 10G 33M 10G 1% /mnt # 3. 向/mnt中写入数据 [root@client1 ~]# cp /etc/hosts /mnt/ [root@client1 ~]# cp /etc/passwd /mnt/ [root@client1 ~]# ls /mnt/ hosts passwd # 4. 创建img1的快照,名为img1-sn1 [root@node1 ~]# rbd snap create img1 --snap img1-sn1 [root@node1 ~]# rbd snap ls img1 SNAPID NAME SIZE 8 img1-sn1 10240 MB # 5. 删除/mnt/中的数据 [root@client1 ~]# rm -f /mnt/* # 6. 通过快照还原数据 [root@client1 ~]# umount /mnt/ [root@client1 ~]# rbd unmap /dev/rbd0 [root@node1 ~]# rbd help snap rollback # 查看子命令帮助 # 回滚img1到快照img1-sn1 [root@node1 ~]# rbd snap rollback img1 --snap img1-sn1 # 重新挂载 [root@client1 ~]# rbd map img1 /dev/rbd0 [root@client1 ~]# mount /dev/rbd0 /mnt/ [root@client1 ~]# ls /mnt/ # 数据还原完成 hosts passwd
2.2保护快照,防止删除
[root@node1 ~]# rbd help snap protect # 保护镜像img1的快照img1-sn1 [root@node1 ~]# rbd snap protect img1 --snap img1-sn1 [root@node1 ~]# rbd snap rm img1 --snap img1-sn1 # 不能删
三、快照克隆
不能将一个镜像同时挂载到多个节点,如果这样操作,将会损坏数据
如果希望不同的节点,拥有完全相同的数据盘,可以使用克隆技术
克隆是基于快照的,不能直接对镜像克隆
快照必须是受保护的快照,才能克隆
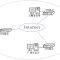
克隆流程
graph LR img(镜像)--创建-->snap(快照) snap--保护-->protect(受保护的快照) protect--克隆-->clone(克隆的镜像)
3.1给多个客户端生成数据相同的数据盘
# 1. 创建名为img2的镜像,大小10GB
[root@node1 ~]# rbd create img2 --size 10G
# 2. 向镜像中写入数据
[root@node1 ~]# rbd map img2
/dev/rbd0
[root@node1 ~]# mkfs.xfs /dev/rbd0
[root@node1 ~]# mount /dev/rbd0 /mnt/
[root@node1 ~]# for i in {1..20}
> do
> echo "Hello World $i" > /mnt/file$i.txt
> done
[root@node1 ~]# ls /mnt/
file10.txt file15.txt file1.txt file5.txt
file11.txt file16.txt file20.txt file6.txt
file12.txt file17.txt file2.txt file7.txt
file13.txt file18.txt file3.txt file8.txt
file14.txt file19.txt file4.txt file9.txt
# 3. 卸载镜像
[root@node1 ~]# umount /mnt/
[root@node1 ~]# rbd unmap /dev/rbd0
# 4. 为img2创建名为img2-sn1快照
[root@node1 ~]# rbd snap create img2 --snap img2-sn1
# 5. 保护img2-sn1快照
[root@node1 ~]# rbd snap protect img2 --snap img2-sn1
# 6. 通过受保护的快照img2-sn1创建克隆镜像
[root@node1 ~]# rbd clone img2 --snap img2-sn1 img2-sn1-1 --image-feature layering
[root@node1 ~]# rbd clone img2 --snap img2-sn1 img2-sn1-2 --image-feature layering
# 7. 查看创建出来的、克隆的镜像
[root@node1 ~]# rbd list
img1
img2
img2-sn1-1
img2-sn1-2
# 8. 不同的客户端挂载不同的克隆镜像,看到的是相同的数据
[root@client1 ~]# rbd map img2-sn1-1
/dev/rbd1
[root@client1 ~]# mkdir /data
[root@client1 ~]# mount /dev/rbd1 /data
[root@client1 ~]# ls /data
file10.txt file15.txt file1.txt file5.txt
file11.txt file16.txt file20.txt file6.txt
file12.txt file17.txt file2.txt file7.txt
file13.txt file18.txt file3.txt file8.txt
file14.txt file19.txt file4.txt file9.txt3.2查询镜像和快照
# 查看快照信息 [root@node1 ~]# rbd info img2 --snap img2-sn1 rbd image 'img2': size 10240 MB in 2560 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.107a238e1f29 format: 2 features: layering flags: protected: True # 受保护 # 查看克隆的快照 [root@node1 ~]# rbd info img2-sn1-2 rbd image 'img2-sn1-2': size 10240 MB in 2560 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.10842eb141f2 format: 2 features: layering flags: parent: rbd/img2@img2-sn1 # 父对象是rbd池中img2镜像的img2-sn1快照 overlap: 10240 MB
3.3合并父子镜像
img2-sn1-2是基于img2的快照克隆来的,不能独立使用。
如果父镜像删除了,子镜像也无法使用。
将父镜像内容合并到子镜像中,子镜像就可以独立使用了。
# 把img2的数据合并到子镜像img2-sn1-2中 [root@node1 ~]# rbd flatten img2-sn1-2 # 查看状态,它就没有父镜像了 [root@node1 ~]# rbd info img2-sn1-2 rbd image 'img2-sn1-2': size 10240 MB in 2560 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.10842eb141f2 format: 2 features: layering flags: # 删除父镜像,如果镜像正在被使用,则先取消 [root@client ~]# umount /data/ [root@client ~]# rbd unmap /dev/rbd1 # 1. 删除镜像img2-sn1-1 [root@node1 ~]# rbd rm img2-sn1-1 # 2. 取消img2-sn1的保护 [root@node1 ~]# rbd snap unprotect img2 --snap img2-sn1 # 3. 删除img2-sn1快照 [root@node1 ~]# rbd snap rm img2 --snap img2-sn1 # 4. 删除img2 [root@node1 ~]# rbd rm img2 # 因为img2-sn1-2已经是独立的镜像了,所以它还可以使用 [root@client1 ~]# rbd list img1 img2-sn1-2 [root@client1 ~]# rbd map img2-sn1-2 /dev/rbd1 [root@client1 ~]# mount /dev/rbd1 /data/ [root@client1 ~]# ls /data/ file10.txt file15.txt file1.txt file5.txt file11.txt file16.txt file20.txt file6.txt file12.txt file17.txt file2.txt file7.txt file13.txt file18.txt file3.txt file8.txt file14.txt file19.txt file4.txt file9.txt
四、ceph文件系统
文件系统:相当于是组织数据存储的方式。
格式化时,就是在为存储创建文件系统。
Linux对ceph有很好的支持,可以把ceph文件系统直接挂载到本地。
要想实现文件系统的数据存储方式,需要有MDS组件
安装并启用mds
# 在node3节点上安装MDS [root@node1 ~]# ssh node3 [root@node3 ~]# yum install -y ceph-mds # 的node1配置MDS [root@node1 ~]# cd ceph-cluster/ [root@node1 ceph-cluster]# ceph-deploy mds create node3
四、使用MDS
4.1新建存储池
归置组PG:存储池包含PG。PG是一个容器,用于存储数据。
为了管理方便,将数量众多的数据放到不同的PG中管理,而不是直接把所有的数据扁平化存放。
通常一个存储池中创建100个PG。
元数据就是描述数据的属性。如属主、属组、权限等。
ceph文件系统中,数据和元数据是分开存储的
创建ceph文件系统
# 1. 新建一个名为data1的存储池,目的是存储数据,有100个PG [root@node1 ceph-cluster]# ceph osd pool create data1 100 # 2. 新建一个名为matadata1的存储池,目的是存储元数据 [root@node1 ceph-cluster]# ceph osd pool create metadata1 100 # 3. 创建名为myfs1的cephfs,数据保存到data1中,元数据保存到metadata1中 [root@node1 ceph-cluster]# ceph fs new myfs1 metadata1 data1 # 查看存储池 [root@node1 ceph-cluster]# ceph osd lspools 0 rbd,1 data1,2 metadata1, [root@node1 ceph-cluster]# ceph df GLOBAL: SIZE AVAIL RAW USED %RAW USED 92093M 91574M 519M 0.56 POOLS: NAME ID USED %USED MAX AVAIL OBJECTS rbd 0 86469k 0.28 30488M 2606 data1 1 0 0 30488M 0 metadata1 2 2068 0 30488M 20
4.2客户端使用cephfs
# 挂载文件系统需要密码。查看密码 [root@client1 ~]# cat /etc/ceph/ceph.client.admin.keyring [client.admin] key = AQBmhINh1IZjHBAAvgk8m/FhyLiH4DCCrnrdPQ== # -t 指定文件系统类型。-o是选项,提供用户名和密码 # cephfs的端口号默认是6789 [root@client1 ~]# mkdir /mydata [root@client1 ~]# mount -t ceph -o name=admin,secret=AQBmhINh1IZjHBAAvgk8m/FhyLiH4DCCrnrdPQ== 192.168.4.13:6789:/ /mydata [root@client1 ~]# df -h /mydata 文件系统 容量 已用 可用 已用% 挂载点 192.168.4.13:6789:/ 90G 520M 90G 1% /mydata
五、对象存储
需要专门的客户端访问
键值对存储方式
对象存储需要rgw组件
安装部署
[root@node1 ceph-cluster]# ssh node3 [root@node3 ~]# yum install -y ceph-radosgw [root@node1 ~]# cd ceph-cluster/ [root@node1 ceph-cluster]# ceph-deploy rgw create node3
客户端使用:http://docs.ceph.org.cn/radosgw/s3/python/
监控前两天用到的主机:
主机名IP地址
zabbixserver192.168.4.5
web1192.168.4.100
web2192.168.4.200
配置yum,关防火墙和selinux







发表评论