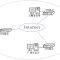
一、主从复制
redis服务的主从复制(与mysql服务主同步的功能一样,都是实现数据自动同步的存储结构。
主服务器:接收客户端连接
从服务器:连接主服务器同步数据
主从复制结构模式:
一主一从 、 一主多从 、 主从从
redis主从复制工作过程(数据同步原理):
!!!说明!!!:从服务器首次做的是全量同步,且同步的数据会覆盖本机的数据
第1步:slave向master发送sync命令
第2步:master启动后台存盘进程,并收集所有修改数据命令
第3步:master完成后台存盘后,传送整个数据文件到slave
第4步:slave接收数据文件,加载到内存中完成首次完全同步,后续有新数据产生时,master继续收集数据修改命令依次传给slave,完成同步
命令行配置命令(马上生效 但不永久 适合配置线上服务器)
info replication #查看复制信息
slaveof 主服务器ip地址 主服务器端口号 #指定主服务服务器IP地址和服务端口号
slaveof no one #临时恢复为主服务器
修改配置文件(永久有效,重启了redis服务依然有效)
]# vim /etc/redis/6379.conf slaveof 主服务器ip地址 主服务器端口号 :wq
!!!说明!!!!
redis服务运行后 默认角色就是master(主)所以一台主机做master 服务器的话 无需配置。
主从结构中的从服务器 都是只读的, 客户端连接从服务器对数据仅有查询权限
配置一主一从
诉求: 把 Redis服务器 host52配置为 redis服务器host51的 slave(从)服务器
!!!说明!!! 运行的redis服务 必须使用本机的 物理网卡口的地址 接收连接请求 (使用默认的lo 地址无法彼此之间建立连接)
[root@host51 ~]# redis-cli -h 192.168.4.51 -p 6379 #host51主机 连接服务 192.168.4.51:6379> info replication #查看复制信息 # Replication role:master 角色是 master connected_slaves:0 从服务器的个数 是 零个 [root@host52 ~]# redis-cli -h 192.168.4.52 -p 6379 #host52主机连接服务 192.168.4.52:6379> info replication # Replication role:master 角色是 master connected_slaves:0 从服务器的个数 是 零个 192.168.4.52:6379> slaveof 192.168.4.51 6379 指定主服务器的ip 和端口 OK #在52主机再次查看复制信息 192.168.4.52:6352> info replication # Replication role:slave 角色变为 slave master_host:192.168.4.51 主服务器ip master_port:6351 主服务器端口 master_link_status:up 能与主服务器连接 如是down 表示连接不上master 服务 .....
把52永久配置为51的从服务器 (host52主机的系统重启 或redis服务重启 都依然是host51的从服务器)
[root@host52 ~]# vim +282 /etc/redis/6379.conf 282 slaveof 192.168.4.51 6379 :wq
#在51主机再次查看复制信息
[root@host51 ~]# redis-cli -h 192.168.4.51 -p 6379 192.168.4.51:6379> info replication # Replication role:master connected_slaves:1 #有1台从服务器 slave0:ip=192.168.4.52,port=6379,state=online,offset=294,lag=0 #从服务器的具体信息
验证配置:
第一步 连接主服务器存储数据
[root@host51 ~]# redis-cli -h 192.168.4.51 -p 6379 192.168.4.51:6379> mset x 1 y 2 z 3 OK 192.168.4.51:6379> keys * 1) "x" 2) "z" 3) "y" 192.168.4.51:6351>
第二步 连接从服务器 能够查看到和主服务器一样的数据
[root@host52 ~]# redis-cli -h 192.168.4.52 -p 6379 192.168.4.52:6379> keys * 1) "z" 2) "y" 3) "x"
说明:主从结构的从服务器不允许执行存储数据的操作
192.168.4.52:6379> set name bob (error) READONLY You can't write against a read only slave. 192.168.4.52:6379>
配置一主多从
诉求: 把Redis服务器host53 也配置为 主机Host51 的slave服务器
在host53主机做如下配置
[root@host53 ~]# redis-cli -h 192.168.4.53 -p 6379 192.168.4.53:6379> slaveof 192.168.4.51 6379 #指定主服务器的ip 和端口 OK
在master服务host51 查看复制信息
[root@host51 ~]# redis-cli -h 192.168.4.51 -p 6379 192.168.4.51:6379> info replication # Replication role:master connected_slaves:2 #有2台从服务器 slave0:ip=192.168.4.52,port=6379,state=online,offset=294,lag=0 slave1:ip=192.168.4.51,port=6379,state=online,offset=294,lag=0
配置主从从结构
在host53主机做如下配置
第1步 把一主多从结构中的host53主机恢复为独立的数据库服务器
第2步:把host53配置为 host52主机的slave服务器
[root@host53 ~]# redis-cli -h 192.168.4.53 -p 6379 192.168.4.53:6379> slaveof no one OK 192.168.4.53:6379> slaveof 192.168.4.52 6379
在host52主机查看复制信息
#既有主服务器的信息又有从服务器的信息
192.168.4.52:6379> info replication # Replication role:slave master_host:192.168.4.51 master_port:6379 master_link_status:up .... connected_slaves:1 slave0:ip=192.168.4.53,port=6379,state=online,offset=2310,lag=0 .....
验证结果 :在host51主机存储数据 , 主机host52 和 host53 都会有同样的数据
[root@host51 ~]# redis-cli -h 192.168.4.51 -p 6379 #连接51 存储数据 192.168.4.51:6379> mset name bob age 19 class nsd2107 OK 192.168.4.51:6379> exit [root@host51 ~]# redis-cli -h 192.168.4.52 -p 6379 #连接52查看数据 192.168.4.52:6379> keys * 1) "age" 2) "class" 3) "name" 192.168.4.52:6379> exit [root@host51 ~]# [root@host51 ~]# redis-cli -h 192.168.4.53 -p 6379 #连接53查看数据 192.168.4.53:6379> keys * 1) "class" 2) "age" 3) "name" 192.168.4.53:6379>
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
案例2:配置带验证的主从复制
意思就是:
主从结构中的master服务器设置了连接密码,
slave服务器要指定连接密码才能正常同步master主机数据
诉求: 给主从从结构中的master 服务器的redis服务设置连接123456 ,slave服务器配置连接master服务服务器密码
第一步 给Redis服务器Host51 设置连接密码 123456
第二步 在redis服务器host52 设置连接 master服务器 host51的连接密码 并设置本机redis服务的连接密码为123456
第三步 在redis服务器host53 设置连接 master服务器 host52的连接密码
第一步:给主服务器51 设置连接密码
[root@host51 ~]# redis-cli -h 192.168.4.51 -p 6379 192.168.4.51:6379> config get requirepass 1) "requirepass" 2) "" 192.168.4.51:6379> config set requirepass 123456 OK 192.168.4.51:6379> config get requirepass (error) NOAUTH Authentication required. 192.168.4.51:6379> 192.168.4.51:6379> auth 123456 OK 192.168.4.51:6379> config get requirepass 1) "requirepass" 2) "123456" 192.168.4.51:6379> config rewrite OK 192.168.4.51:6379> exit [root@host51 ~]# tail -1 /etc/redis/6379.conf requirepass "123456" [root@host51 ~]#
第二步 :配置redis服务器 host52
[root@host52 ~]# redis-cli -h 192.168.4.52 -p 6379 192.168.4.52:6379> config get requirepass 1) "requirepass" 2) "" 192.168.4.52:6379> config set requirepass 123456 OK 192.168.4.52:6379> auth 123456 OK 192.168.4.52:6379> config get masterauth 1) "masterauth" 2) "" 192.168.4.52:6379> config set masterauth 123456 OK 192.168.4.52:6379> config get masterauth 1) "masterauth" 2) "123456" 192.168.4.52:6379> config rewrite OK 192.168.4.52:6379> 192.168.4.52:6379> info replication 192.168.4.52:6379> info replication # Replication role:slave master_host:192.168.4.51 master_port:6379 master_link_status:up .... .... 192.168.4.52:6379> exit [root@host52 redis-4.0.8]# tail -2 /etc/redis/6379.conf masterauth "123456" requirepass "123456" [root@host52 redis-4.0.8]#
第三步 在redis服务器host53 设置连接 master服务器 host52的连接密码
[root@host53 ~]# redis-cli -h 192.168.4.53 192.168.4.53:6379> config set masterauth 123456 OK 192.168.4.53:6379> slaveof 192.168.4.52 6379 OK 192.168.4.53:6379> config rewrite OK 192.168.4.53:6379> 192.168.4.53:6379> info replication # Replication role:slave master_host:192.168.4.52 master_port:6379 master_link_status:up .... 192.168.4.53:6379> exit
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
案例3:哨兵服务
什么是哨兵服务:监视主从复制结构中主服务器,发现主服务器无法连接后,会把对应的从升级为主数据库服务器,继续监视新的主数据库服务器,坏掉的主数据库服务器恢复后,会自动做当前主服务器的从主机。哨兵服务+redis主从服务 能够实现redis服务高可用和数据的自动备份,但远比Redis集群的资金成本和运维成本要低。
说明:
1)可以使用一主一从或 一主多从 或 主从从 + 哨兵服务 做服务的高可用 和 数据自动备份
2)如果主从结构中的redis服务设置连接密码的话必须全每台数据库都要设置密码且密码要一样,
3)宕机的服务器 启动服务后,要人为指定主服务器的连接密码
诉求: 192.168.4.57 主机做哨兵服务器 + 主从从结构 实现redis服务的高可用
步骤一 给host53主机的Redis服务设置连接密码 要与另外2台Redis服务器设置一样的连接密码
[root@host53 ~]# redis-cli -h 192.168.4.53 192.168.4.53:6379> config set requirepass 123456 OK 192.168.4.53:6379> auth 123456 OK 192.168.4.53:6379> config rewrite OK 192.168.4.53:6379>
步骤二:配置哨兵服务(192.168.4.57)
具体操作步骤:
1)安装源码软件redis (无需做初始化配置,如果做了初始化把redis服务停止即可)
2)创建并编辑主配置文件 (说明源码包里有哨兵服务配置文件的模板sentinel.conf)
1) 安装源码软件redis (无需做初始化配置,如果做了初始化把redis服务停止即可)
[root@redis57 ~ ]# yum -y install gcc [root@redis57 ~ ]# tar -zxf redis-4.0.8.tar.gz [root@redis57 redis]# cd redis-4.0.8/ [root@redis1 redis-4.0.8]# make [root@redis1 redis-4.0.8]# make install
2)创建并编辑主配置文件
#说明源码包里有哨兵服务配置文件的模板sentinel.conf
[root@host57 ~]# vim /etc/sentinel.conf bind 192.168.4.57 sentinel monitor redis_server 192.168.4.51 6379 1 sentinel auth-pass redis_server 123456 #如果主服务器没有连接密码此配置项可用省略 :wq
3)启动哨兵服务 (会占用当前终端显示启动信息)
[root@mgm57 redis-4.0.8]# nohup redis-sentinel /etc/sentinel.conf & [1] 5701 [root@mgm57 redis-4.0.8]# nohup: #忽略输入并把输出追加到"nohup.out" 回车即可 [root@mgm57 redis-4.0.8]# jobs 查看当前终端后台进程 [1]+ 运行中 nohup redis-sentinel /etc/sentinel.conf & [root@mgm57 redis-4.0.8]#
步骤二:测试配置
1)停止主服务器51的redis服务
[root@host51 ~]# redis-cli -h 192.168.4.51 -p 6379 -a 123456 shutdown
2)在服务器52主机,查看复制信息, 角色为 master
[root@host52 ~]# redis-cli -h 192.168.4.52 -p 6379 -a 123456 192.168.4.52:6379> info replication #角色是master 只有一个从 # Replication role:master connected_slaves:1 slave0:ip=192.168.4.53,port=6379,state=online,offset=144080,lag=0
192.168.4.52:6379> mset v1 101 v2 102 存储数据 OK
3)查看哨兵服务主配置文件 监视的主服务器 自动修改为 从服务器的ip
[root@host57 ~]# cat /etc/sentinel.conf ..... sentinel monitor redis_server 192.168.4.52 6379 1 ..... sentinel auth-pass redis_server 123456 sentinel known-slave redis_server 192.168.4.53 6379 sentinel known-slave redis_server 192.168.4.51 6379 ..... [root@host57 ~]#
4) 把宕机51主机的redis服务启动 ,会自动做当前主服务器52的从主机
[root@host51 ~]# /etc/init.d/redis_6379 start Starting Redis server... [root@host51 ~]# redis-cli -h 192.168.4.51 -p 6379 -a 123456 192.168.4.51:6379> 192.168.4.51:6379> info replication # Replication role:slave master_host:192.168.4.52 master_port:6379 master_link_status:down 没有设置连接密码是down状态 192.168.4.51:6379> config set masterauth 123456 设置连接主服务器密码 OK 192.168.4.51:6379> config rewrite 保存到配置文件 OK 192.168.4.51:6379> 192.168.4.51:6379> info replication # Replication role:slave master_host:192.168.4.52 master_port:6379 master_link_status:up 连接是up状态
5)在host52主机查看复制信息
192.168.4.52:6379> info replication # Replication role:master connected_slaves:2 有2个从服务器 slave0:ip=192.168.4.53,port=6379,state=online,offset=231667,lag=0 slave1:ip=192.168.4.52,port=6379,state=online,offset=231667,lag=0
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
二、持久化 (理论多)
2.1、什么是持久化: redis服务可以永久的保存数据,怎么实现的呢?
2.2、实现方式有2种:分别是 RDB文件 和 AOF文件
1) RDB文件
指定就是数据库目录下的 dump.rdb 文件
redis运行服务后,会根据配置文件的设置的存盘频率 把内存里的数据复制到数据库目录下的dump.rdb文件里(覆盖保存)
2)AOF文件
redis服务AOF文件(与mysql服务的binlog日志文件的功能相同)
是一个文件,记录连接redis服务后执行的写操作命令并且是以追加的方式记录写操作命令
默认没有开启,使用需要人为启用。
!!!说明:通过这2种文件 均可以实现对数据的手动备份和手动恢复!!!
2.4、RDB文件的使用
2.4.1、查看 redis服务存储数据到硬盘的存盘频率
vim /etc/redis/6379.conf (默认 219行 220行 221行)
save 秒 变量的个数
save 900 1
save 300 10
save 60 10000
2.4.2、验证配置文件里定义的存储频率
[root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 shutdown [root@host56 ~]# rm -rf /var/lib/redis/6379/* [root@host56 ~]# vim +219 /etc/redis/6379.conf save 900 1 #save 300 10 save 120 10 # 2分钟内且有>=10个变量改变 就把内存里的数据复制到dump.rdb文件里 save 60 10000 :wq
[root@host56 ~]# /etc/init.d/redis_6379 start Starting Redis server... [root@host56 ~]# [root@host56 ~]# ls /var/lib/redis/6379/dump.rdb ls: 无法访问/var/lib/redis/6379/dump.rdb: 没有那个文件或目录 [root@host56 ~]# [root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 (在服务启动后,要在2分钟内存储大于等10个变量) 192.168.4.56:6379> mset a 1 b 2 c 3 d 4 OK 192.168.4.56:6379> mset x 1 y 2 z 3 k 6 i 7 z 9 f 22 zz 99 cc 66
192.168.4.56:6379> exit [root@host56 ~]# ls /var/lib/redis/6379/ dump.rdb [root@host56 ~]# ls /var/lib/redis/6379/ -l 显示文件创建的时间 总用量 4 -rw-r--r-- 1 root root 159 10月 26 16:30 dump.rdb [root@host56 ~]#
2.4.3、使用RDB文件 实现数据的备份和恢复
第1步:拷贝 dump.rdb 文件就是对数据的备份
[root@host56 ~]# cp /var/lib/redis/6379/dump.rdb /opt/ [root@host56 ~]# ls /opt/*.rdb /opt/dump.rdb [root@host56 ~]#
第2步:把备份的 dump.rdb 文件 再次拷贝回数据库目录就是恢复
#误删除数据
192.168.4.56:6379> FLUSHALL OK 192.168.4.56:6379> keys * (empty list or set) 192.168.4.56:6379>
#使用备份的dump.rdb文件恢复
第1步 停止内存没有数据的redis服务
第2步 把没有数据的dump.rdb文件删除
第3步 把备份dump.rdb文件拷贝到数据库目录下
第4步 启动redis服务 并连接服务查看数据
[root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 shutdown [root@host56 ~]# rm -rf /var/lib/redis/6379/dump.rdb [root@host56 ~]# cp /opt/dump.rdb /var/lib/redis/6379/ [root@host56 ~]# /etc/init.d/redis_6379 start Starting Redis server... [root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 192.168.4.56:6379> keys * 1) "i" 2) "d" 3) "x"
2.4.4 RDB方式的优/缺点
优点:
高性能的持久化实现 —— 创建一个子进程来执行持久化,先将数据写入临时文件,持久化过程结束后,再用这个临时文件替换上次持久化好的文件;
过程中主进程不做任何IO操作比较适合大规模数据恢复,且对数据完整性要求不是非常高的场合
缺点:意外宕机时,丢失最后一次持久化的所有数据
2.5 AOF文件的使用
2.5.1 启用AOF文件
1、通过修改配置文件启用(修改文件需要重启redis服务才能生效,所以时适合线下服务器)
注意:通过配置文件启用AOF文件 服务器原有的数据会被删除
[root@host53 ~]# redis-cli -h 192.168.4.53 -p 6379 shutdown [root@host53 ~]# vim /etc/redis/6379.conf appendonly yes 启用 aof 文件 appendfilename "appendonly.aof" 日志文件名 :wq [root@host53 ~]# /etc/init.d/redis_6379 start Starting Redis server... [root@host53 ~]# [root@host53 ~]# ls /var/lib/redis/6379/ 存放在日志目录下 appendonly.aof dump.rdb [root@host56 ~]# wc -l /var/lib/redis/6379/appendonly.aof 刚启用日志 文件里1条命令也没记录 0 /var/lib/redis/6379/appendonly.aof [root@host56 ~]# 连接服务存储数据后 再查看文件行数 [root@host53 ~]# redis-cli -h 192.168.4.53 -p 6379 192.168.4.53:6379> keys * 删除了服务器原有的数据 (empty list or set) 192.168.4.53:6379> 192.168.4.56:6379> set a 1 OK 192.168.4.56:6379> mset b 2 c 3 d 4 e 5 OK 192.168.4.56:6379> keys * 1) "c" 2) "a" 3) "b" 4) "e" 5) "d" 192.168.4.56:6379> exit [root@host56 ~]# wc -l /var/lib/redis/6379/appendonly.aof 31 /var/lib/redis/6379/appendonly.aof [root@host56 ~]#
命令行启动(马上生效且不需要重启redis服务,也不会删除原有的数据 所以适合线上服务器)
[root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 192.168.4.56:6356> config set appendonly yes 启用aof文件 OK 192.168.4.56:6356> config rewrite 永久有效 OK 192.168.4.56:6356> keys * (empty list or set) 192.168.4.56:6356> set x 1 OK 192.168.4.56:6356> set y 2 OK 192.168.4.56:6356> set z 3 OK 192.168.4.56:6356> keys * 1) "x" 2) "z" 3) "y" 192.168.4.56:6356> exit [root@host56 ~]# ls /var/lib/redis/6379/*.aof 数据库目录多了.aof文件 /var/lib/redis/6379/appendonly.aof [root@host56 ~]# ls /var/lib/redis/6379/*.rdb /var/lib/redis/6379/dump.rdb [root@host56 ~]#
2.5.2 使用AOF文件 实现数据的备份和恢复
第1步 备份aof文件
[root@host56 ~]# cp /var/lib/redis/6379/appendonly.aof /opt/ [root@host56 ~]# ls /opt/*.aof /opt/appendonly.aof [root@host56 ~]#
第2步 使用备份的aof文件恢复数据
#删除数据
[root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 192.168.4.56:6379> flushall 192.168.4.56:6379> exit
#恢复数据
第1步: 把没有数据的服务停止
[root@host56 ~]# redis-cli -h 192.168.4.56 -p 6356 shutdown
第2步: 删除没有数据的aof文件和rdb文件
[root@host56 ~]# rm -rf /var/lib/redis/6379/*
第3步:把备份的aof文件拷贝到数据库目录
[root@host56 ~]# cp /opt/appendonly.aof /var/lib/redis/6379/
第4步:启动redis服务并查看数据
[root@host56 ~]# /etc/init.d/redis_6379 start Starting Redis server... [root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 192.168.4.56:6379> keys * 1) "v4" 2) "v3"
使用自带命令修改有问题的aof文件
命令格式
[root@host56 ~]# redis-check-aof --fix /目录名/日志文件名 [root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 shutdown 停止服务 [root@host56 ~]# echo "daaaa" >> /var/lib/redis/6379/appendonly.aof 在日志追加错误格式的命令 [root@host56 ~]# /etc/init.d/redis_6379 start 启动服务 Starting Redis server... [root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 连接服务 Could not connect to Redis at 192.168.4.56:6379: Connection refused 提示连接失败 说明服务没启动 Could not connect to Redis at 192.168.4.56:6379: Connection refused not connected> exit 退出登录提示
[root@host56 ~]# tail -1 /var/log/redis_6379.log 查看日志文件的最后1行 (最新的日志信息都记录在日志文件的末尾) ,会显示报错原因的解决办法 5662:M 26 Nov 16:53:09.530 # Bad file format reading the append only file: make a backup of your AOF file, then use ./redis-check-aof --fix <filename>
[root@host56 ~]# redis-check-aof --fix /var/lib/redis/6379/appendonly.aof 恢复日志 0x 78: Expected prefix '*', got: 'd' AOF analyzed: size=126, ok_up_to=120, diff=6 This will shrink the AOF from 126 bytes, with 6 bytes, to 120 bytes Continue? [y/N]: y 同意修复 Successfully truncated AOF
[root@host56 ~]# /etc/init.d/redis_6379 start 启动服务 /var/run/redis_6379.pid exists, process is already running or crashed 提示PID文件存储 [root@host56 ~]# rm -rf /var/run/redis_6379.pid 删除文件
[root@host56 ~]# /etc/init.d/redis_6379 start 启动服务 Starting Redis server... [root@host56 ~]# redis-cli -h 192.168.4.56 -p 6379 连接服务查看数据 192.168.4.56:6379> keys * 查看数据 1) "a" 2) "e" 3) "b" 4) "c" 5) "d" 192.168.4.56:6379>
2.5.4 与aof 相关的配置项 ( vim /etc/redis/6379.conf )
appendfsync always //时时记录,并完成磁盘同步
appendfsync everysec //每秒记录一次,并完成磁盘同步
appendfsync no //写入aof ,不执行磁盘同步
auto-aof-rewrite-min-size 64mb //首次重写触发值
auto-aof-rewrite-percentage 100 //再次重写,增长百分比
2.5.6 AOF文件的优缺点
AOF优点
可以灵活设置持久化方式
出现意外宕机时,仅可能丢失1秒的数据
AOF缺点
持久化文件的体积通常会大于RDB方式
执行fsync策略时的速度可比RDB方式慢
三、数据类型(操作多 ,主要掌握对不同类型数据的管理命令)
在数据是通过程序员写网站脚本存储在 redis 服务器的内存里。
数据库运维需要对存储在服务器内存里的数据做管理,
管理包括: 查看 修改 删除 存储新数据 ,不同类型的数据要使用对应的命令管理
redis服务支持的数据类型如下:
1) 字符类型( string) 字符串 可以是英文字母 或 汉字
2) 列表类型 (list) 一个变量名 存储多个数据 (类似于shell脚本语言的数组)
3)Hash 类型 (hash) 一个变量里可以存储多列 每列对应一个值
4)集合类型 也是让一个变量可以存储多个数据 (和python 语言集合类型是一个意思)
集合分为有序集合类型(zset) 和 无序集合类型( set)
工作如何对程序存储在内存里的数据做管理
第1步 查看变量是否存在
192.168.4.56:6356> EXISTS NAME
(integer) 0 表示不存在
192.168.4.56:6356> EXISTS age
(integer) 1 表示变量存在
192.168.4.56:6356>
第2步 查看数据类型 (知道数据类型后,才能明确用来管理命令)
注意: 每种类型的数据都是用固定的关键字表示
192.168.4.56:6356> type age
string
192.168.4.56:6356>
第3步:掌握每种类型数据对应的管理命令
操作命令包括: 变量赋值 查看变量值 修改变量值 输出变量值
~~~~~~~~~~~~~~~~数据类型的使用~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
### 字符类型 string
- 字符串类型是 Redis 中最基本的数据类型,它能存储任何形式的字符串,包括二进制数据
- 可以用其存储用户的邮箱、JSON 化的对象甚至是一张图片
- 一个字符串类型键允许存储的数据的最大容量是512 MB
- 字符串类型是其他4种数据类型的基础,其他数据类型和字符串类型的差别从某种角度来说只是组织字符串的形式不同
#### 字符串操作命令
- 赋值命令
# 赋值 SET key value
# 取值 GET key
- 赋值命令示例
127.0.0.1:6379> SET username tom OK 127.0.0.1:6379> GET username "tom" 127.0.0.1:6379> GET password # 当键不存在时会返回空结果。 (nil)
存储变量是 设置变量的有效期 px(毫秒) ex (秒)
192.168.4.51:6379> set name plj ex 10 OK 192.168.4.51:6379> 192.168.4.51:6379> set name plj px 10 OK 192.168.4.51:6379>
NX 变量不存在是赋值 如果存在就放弃赋值
192.168.4.51:6379> set name plj NX OK 192.168.4.51:6379> get name "plj"
XX 变量存在时赋值 如果不存在放弃赋值
192.168.4.51:6379> set name yaya XX OK 192.168.4.51:6379> get name "yaya" 192.168.4.51:6379>
set 命令完整格式演示
192.168.4.51:6379> set password 12345 ex 20 NX OK 192.168.4.51:6379>
- 递增数字:字符串类型可以存储任何形式的字符串,当存储的字符串是整数形式时,
Redis 提供了一个实用的命令 INCR,其作用是让当前键值递增,并返回递增后的值。
# 当要操作的键不存在时会默认键值为0,所以第一次递增后的结果是1。
127.0.0.1:6379> INCR num (integer) 1 127.0.0.1:6379> INCR num (integer) 2 127.0.0.1:6379> GET num "2"
- 当键值不是整数时Redis会提示错误
127.0.0.1:6379> SET foo bar OK 127.0.0.1:6379> INCR foo (error) ERR value is not an integer or out of range
- 增加指定的整数
127.0.0.1:6379> INCRBY num 2 (integer) 4 127.0.0.1:6379> INCRBY num 2 (integer) 6
- 递减数字
127.0.0.1:6379> DECR num (integer) 5 127.0.0.1:6379> DECRBY num 2 (integer) 3
- 向尾部追加值
127.0.0.1:6379> SET hi Hello OK
127.0.0.1:6379> APPEND hi " World" # 因为字符串包含空格,需要使用引号 (integer) 11 # 返回值为hi的总长度
127.0.0.1:6379> GET hi "Hello World"
- 获取字符串长度
127.0.0.1:6379> STRLEN hi (integer) 11
- 中文字符返回字节数
127.0.0.1:6379> SET name 张三 OK 127.0.0.1:6379> STRLEN name (integer) 6 # UTF-8编码的中文,由于“张”和“三”两个字的UTF-8编码的长度都是3,所以此例中会返回6。
获取变量部分数据
192.168.4.53:6379> set zfc ABCEF OK 192.168.4.53:6379> GET zfc "ABCEF" 192.168.4.53:6379> GETRANGE zfc 0 1 "AB" 192.168.4.53:6379> GETRANGE zfc 2 4 "CEF" 192.168.4.53:6379> GETRANGE zfc -2 -1 "EF" 192.168.4.53:6379>
#### 字符串实践
- Redis 对于键的命名并没有强制的要求,但比较好的实践是用“对象类型:对象ID:对象属性”来命名一个键,如使用键【`user:1:friends`】来存储ID为1的用户的好友列表。
- 例:如果你正在编写一个博客网站,博客的一个常见的功能是统计文章的访问量,我们可以为每篇文章使用一个名为【`post:文章ID:page.view`】的键来记录文章的访问量,每次访问文章的时候使用INCR命令使相应的键值递增。
# 有用户访问文章ID号为42的博文,则将其访问计数加1
127.0.0.1:6379> INCR post:42:page.view (integer) 1 127.0.0.1:6379> GET post:42:page.view "1" 127.0.0.1:6379> INCR post:42:page.view (integer) 2 127.0.0.1:6379> GET post:42:page.view "2" ```
### 散列类型
- 散列类型(hash)的键值也是一种字典结构,其存储了字段(field)和字段值的映射
- 字段值只能是字符串
- 散列类型适合存储对象。使用对象类别和 ID 构成键名,使用字段表示对象的属性,而字段值则存储属性值
#### 散列类型操作命令
- 赋值与取值
127.0.0.1:6379> HSET user1 name bob (integer) 1 127.0.0.1:6379> HSET user1 gender male (integer) 1 127.0.0.1:6379> HGET user1 name "bob" 127.0.0.1:6379> HGET user1 gender "male"
# 设置多个字段
127.0.0.1:6379> HMSET user1 email bob@tedu.cn phone 13412345678 OK 127.0.0.1:6379> HMGET user1 email phone 1) "bob@tedu.cn" 2) "13412345678"
# 获取所有字段
127.0.0.1:6379> HGETALL user1 1) "name" 2) "bob" 3) "gender" 4) "male" 5) "email" 6) "bob@tedu.cn" 7) "phone" 8) "13412345678" ```
- 判断
# 判断字段是否存在
127.0.0.1:6379> HEXISTS user1 address (integer) 0 127.0.0.1:6379> HEXISTS user1 name (integer) 1
# 当字段不存在时赋值
127.0.0.1:6379> HSETNX user1 address beijing (integer) 1 127.0.0.1:6379> HSETNX user1 address beijing (integer) 0
- 数字递增
127.0.0.1:6379> HINCRBY user1 age 20 (integer) 20 127.0.0.1:6379> HINCRBY user1 age 1 (integer) 21
- 删除字段
127.0.0.1:6379> HDEL user1 age (integer) 1
- 只获取字段名
127.0.0.1:6379> HKEYS user1 1) "name" 2) "gender" 3) "email" 4) "phone" 5) "address"
- 只获取值
127.0.0.1:6379> HVALS user1 1) "bob" 2) "male" 3) "bob@tedu.cn" 4) "13412345678" 5) "beijing" ```
- 获得字段数量
127.0.0.1:6379> HLEN user1 (integer) 5
#### 散列类型实践
- 例:将文章ID号为10的文章以散列类型存储在Redis中
127.0.0.1:6379> HSET post:10 title 例解Python (integer) 1 127.0.0.1:6379> HGETALL post:10 1) "title" 2) "\xe4\xbe\x8b\xe8\xa7\xa3Python" 127.0.0.1:6379> HSET post:10 author ZhangZhiGang (integer) 1 127.0.0.1:6379> HMSET post:10 date 2021-05-01 summary 'Python Programming' OK
127.0.0.1:6379> HGETALL post:10 1) "title" 2) "\xe4\xbe\x8b\xe8\xa7\xa3Python" 3) "author" 4) "ZhangZhiGang" 5) "date" 6) "2021-05-01" 7) "summary" 8) "Python Programming" ```
### 列表类型
- 列表类型(list)可以存储一个有序的字符串列表
- 常用的操作是向列表两端添加元素,或者获得列表的某一个片段
- 列表类型内部是使用双向链表(double linked list)实现的,获取越接近两端的元素速度就越快
- 使用链表的代价是通过索引访问元素比较慢
- 这种特性使列表类型能非常快速地完成关系数据库难以应付的场景:如社交网站的新鲜事,我们关心的只是最新的内容,使用列表类型存储,即使新鲜事的总数达到几千万个,获取其中最新的100条数据也是极快的
#### 列表类型操作命令
- LPUSH命令用来向列表左边增加元素,返回值表示增加元素后列表的长度
127.0.0.1:6379> LPUSH numbers 1 (integer) 1 127.0.0.1:6379> LPUSH numbers 2 3 (integer) 3
- 取出列表所有元素
127.0.0.1:6379> LRANGE numbers 0 -1 # 起始下标为0,结束下标为-1 1) "3" 2) "2" 3) "1" ```
- RPUSH命令用来向列表左边增加元素,返回值表示增加元素后列表的长度
127.0.0.1:6379> RPUSH numbers 0 -1 (integer) 5 127.0.0.1:6379> LRANGE numbers 0 -1 1) "3" 2) "2" 3) "1" 4) "0" 5) "-1"
- 从列表两端弹出元素
127.0.0.1:6379> LPOP numbers "3" 127.0.0.1:6379> LRANGE numbers 0 -1 1) "2" 2) "1" 3) "0" 4) "-1"
127.0.0.1:6379> RPOP numbers "-1" 127.0.0.1:6379> LRANGE numbers 0 -1 1) "2" 2) "1" 3) "0"
- 获取列表中元素的个数
127.0.0.1:6379> LLEN numbers (integer) 3
- 获得/设置指定索引的元素值
# 获取numbers列表中下标为0的值
127.0.0.1:6379> LINDEX numbers 0 "2"
# 设置下标为1的值为10
127.0.0.1:6379> LSET numbers 1 10 OK 127.0.0.1:6379> LRANGE numbers 0 -1 1) "2" 2) "10" 3) "2" 4) "1" 5) "2" 6) "1" 7) "2" 8) "1" 9) "2" 10) "1" 11) "2" 12) "1"
127.0.0.1:6379> LRANGE numbers 0 -1 1) "2" 2) "10" 3) "2" ```
- 插入元素
# 在2的前面插入20
127.0.0.1:6379> LINSERT numbers BEFORE 2 20 (integer) 4 127.0.0.1:6379> LRANGE numbers 0 -1 1) "20" 2) "2" 3) "10" 4) "2"
# 在2的后面挺入30
127.0.0.1:6379> LINSERT numbers AFTER 2 30 (integer) 5 127.0.0.1:6379> LRANGE numbers 0 -1 1) "20" 2) "2" 3) "30" 4) "10" 5) "2" ```
#### 列表类型实践
- 例:记录最新的10篇博文
```shell 127.0.0.1:6379> LPUSH posts:list 11 12 13 (integer) 3 127.0.0.1:6379> LRANGE posts:list 0 -1 1) "13" 2) "12" 3) "11" ```
### 集合类型
- 集合中的每个元素都是不同的,且没有顺序
- 增加/删除元素
127.0.0.1:6379> SADD letters a b c (integer) 3 127.0.0.1:6379> SADD letters b c d (integer) 1 127.0.0.1:6379> SMEMBERS letters 1) "d" 2) "b" 3) "a" 4) "c" 127.0.0.1:6379> SREM letters a c (integer) 2 127.0.0.1:6379> SMEMBERS letters 1) "d" 2) "b" ```
- 判断元素是否在集合中
127.0.0.1:6379> sismember letters a (integer) 0 127.0.0.1:6379> sismember letters b (integer) 1 ```
- 集合运算
192.168.4.51:6379> sadd s1 a b c (integer) 3 192.168.4.51:6379> sadd s2 b c d (integer) 3 192.168.4.51:6379> 192.168.4.51:6379> SINTER s1 s2 1) "c" 2) "b"
127.0.0.1:6379> SUNION s1 s2 1) "a" 2) "c" 3) "b" 4) "d"
127.0.0.1:6379> SDIFF s1 s2 1) "a"
- 获得集合中元素个数
127.0.0.1:6379> SCARD letters (integer) 2 ```
- 随机获得集合中的元素
# 在集合s1中随机取出两个不同元素。
127.0.0.1:6379> SRANDMEMBER s1 2 1) "b" 2) "c"
# 在集合s1中随机取出两个有可能相同元素。
127.0.0.1:6379> SRANDMEMBER s1 -2 1) "c" 2) "c"
127.0.0.1:6379> SRANDMEMBER s1 -2 1) "a" 2) "b" ```
- 集合中随机弹出一个元素
127.0.0.1:6379> SPOP s1 "a" 127.0.0.1:6379> SMEMBERS s1 1) "b" 2) "c"
#### 集合实践
- 例:为文章号为10的博客文章添加标签
127.0.0.1:6379> SADD post:10:tags python redis nginx (integer) 3 127.0.0.1:6379> SMEMBERS post:10:tags 1) "python" 2) "nginx" 3) "redis"
### 有序集合类型
- 在集合类型的基础上有序集合类型为集合中的每个元素都关联了一个分数
- 这使得我们不仅可以完成插入、删除和判断元素是否存在等集合类型支持的操作,还能够获得分数最高(或最低)的前N个元素、获得指定分数范围内的元素等与分数有关的操作
- 虽然集合中每个元素都是不同的,但是它们的分数却可以相同。
- 有序集合类型在某些方面和列表类型有些相似
- 二者都是有序的
- 二者都可以获得某一范围的元素
- 有序集合类型和列表也有着很大的区别,这使得它们的应用场景也是不同的
- 列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会较慢,所以它更加适合实现如“新鲜事”或“日志”这样很少访问中间元素的应用
- 有序集合类型是使用散列表和跳跃表(Skip list)实现的,所以即使读取位于中间部分的数据速度也很快
- 列表中不能简单地调整某个元素的位置,但是有序集合可以(通过更改这个元素的分数)
- 有序集合要比列表类型更耗费内存
#### 有序集合类型操作
- ZADD 命令用来向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数替换原有的分数。
ZADD命令的返回值是新加入到集合中的元素个数
127.0.0.1:6379> ZADD scores 88 tom 90 jerry 75 bob 92 alice (integer) 4 127.0.0.1:6379> ZRANGE scores 0 -1 1) "bob" 2) "tom" 3) "jerry" 4) "alice"
127.0.0.1:6379> ZRANGE scores 0 -1 WITHSCORES 1) "bob" 2) "75" 3) "tom" 4) "88" 5) "jerry" 6) "90" 7) "alice" 8) "92"
127.0.0.1:6379> ZADD scores 85 jerry (integer) 0 127.0.0.1:6379> ZRANGE scores 0 -1 WITHSCORES 1) "bob" 2) "75" 3) "jerry" 4) "85" 5) "tom" 6) "88" 7) "alice" 8) "92"
- 获得元素的分数
127.0.0.1:6379> ZSCORE scores tom "88" ```
- 获得指定分数范围的元素
127.0.0.1:6379> ZRANGEBYSCORE scores 80 90 WITHSCORES 1) "jerry" 2) "85" 3) "tom" 4) "88"
- 增加某个元素的分数
127.0.0.1:6379> ZINCRBY scores 3 bob "78" 127.0.0.1:6379> ZSCORE scores bob "78"
- 获得集合中元素的数量
127.0.0.1:6379> ZCARD scores (integer) 4
- 获得指定分数范围内的元素个数
127.0.0.1:6379> ZCOUNT scores 80 90 (integer) 2
- 删除元素
127.0.0.1:6379> ZREM scores bob (integer) 1
- 获得元素的排名
127.0.0.1:6379> ZRANK scores tom # 获取tom的排名 (integer) 1 # 升序排列,从0开始计数 127.0.0.1:6379> ZREVRANK scores alice # 获取alice的排名 (integer) 0 # 降序排列,从0开始计数 ```
#### 有序集合类型实践
- 例:将博客文章按照点击量排序
```shell 127.0.0.1:6379> ZADD posts:page.view 0 post:10:page.view (integer) 1 127.0.0.1:6379> ZINCRBY posts:page.view 1 post:10:page.view "1" 127.0.0.1:6379> ZRANGE posts:page.view 0 -1 WITHSCORES 1) "post:10:page.view" 2) "1" ```
##
over







发表评论