模块基础
定义模块
基本概念
模块是从逻辑上组织python代码的形式
当代码量变得相当大的时候,最好把代码分成一些有组织的代码段,前提是保证它们的 彼此交互
这些代码片段相互间有一定的联系,可能是一个包含数据成员和方法的类,也可能是一组相关但彼此独立的操作函数
导入模块 (import)
使用 import 导入模块
模块属性通过 “模块名.属性” 的方法调用
如果仅需要模块中的某些属性,也可以单独导入
为什么需要导入模块?
可以提升开发效率,简化代码
图例

正确使用
# test.py,将 file_copy.py 放在同级目录下 # 需求:要将/etc/passwd复制到/tmp/passwd src_path = "/etc/passwd" dst_path = "/tmp/passwd" # 如何复制? # 调用已有模块中的方法 # - 很推荐,简单粗暴不动脑 # - 直接使用 file_copy.py的方法即可 # 导入方法一:直接导入模块 import file_copy # 要注意路径问题 file_copy.copy(src_path, dst_path) # 导入方法二:只导入 file_copy 模块的 copy 方法 from file_copy import copy # 如果相同时导入多个模块 from file_copy import * copy(src_path, dst_path) # 导入方法四:导入模块起别名 as import file_copy as fc fc.copy(src_path, dst_path)
常用的导入模块的方法
一行指导入一个模块,可以导入多行, 例如:import random
只导入模块中的某些方法,例如:from random import choice, randint
模块加载 (load)
一个模块只被 加载一次,无论它被导入多少次
只加载一次可以 阻止多重导入时,代码被多次执行
如果两个文件相互导入,防止了无限的相互加载
模块加载时,顶层代码会自动执行,所以只将函数放入模块的顶层是最好的编程习惯
模块特性及案例
模块特性
模块在被导入时,会先完整的执行一次模块中的 所有程序
案例
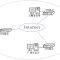
# foo.py print(__name__) # bar.py import foo # 导入foo.py,会将 foo.py 中的代码完成的执行一次,所以会执行 foo 中的 print(__name__)
结果:
# foo.py -> __main__ 当模块文件直接执行时,__name__的值为‘__main__’ # bar.py -> foo 当模块被另一个文件导入时,__name__的值就是该模块的名字
如何理解?图例:

所以我们以后在 Python 模块中执行代码的标准格式:
def test(): ...... if __name__ == "__main__": test()
练习:生成随机密码
创建 randpass.py 脚本,要求如下:
编写一个能生成 8 位随机密码的程序
使用 random 的 choice 函数随机取出字符
改进程序,用户可以自己决定生成多少位的密码
版本一:
import random # 调用随机数模块random # 定义变量all_chs,存储密码的所有选择; # 定义变量result,存储8位随机数,初值为'' all_chs = '1234567890abcdefghigklmnopqrstuvwxyzABCDEFGHIGKLMNOPQLMNUVWXYZ' result = '' #使用for循环,循环8次,每次从all_chs中随机产生一个字符,拼接到result中 for i in range(8): ch = random.choice(all_chs) result += ch print(result) # 输出结果,右键执行【Run 'randpass'】,查看结果
版本二(优化):函数化程序,并可以指定密码长度,在randpass.py文件中操作
import random # 调用随机数模块random # 定义变量all_chs,存储密码的所有选择; all_chs = '1234567890abcdefghigklmnopqrstuvwxyzABCDEFGHIGKLMNOPQLMNUVWXYZ' def randpass(n=8): # 使用def定义函数randpass(), 生成随机8位密码 result = '' for i in range(n): ch = random.choice(all_chs) result += ch return result # return给函数返回密码 if __name__ == '__main__': # 测试代码块,__name__作为python文件调用时,执行代码块 print(randpass(8)) print(randpass(4))
版本三:随机密码的字符选择可以调用模块
# 调用随机数模块random # string模块中的变量ascii_letters和digits中,定义了大小写字母和所有数字 # 【Ctrl + 鼠标左键】可以看到 ascii_letters 的模块文件内容 import random from string import ascii_letters, digits # 定义变量all_chs,存储密码的所有选择; all_chs = ascii_letters + digits # 使用def定义函数randpass(), 生成随机8位密码 def randpass(n=8): result = '' for i in range(n): ch = random.choice(all_chs) result += ch return result # return给函数返回密码 # 测试代码块,__name__作为python文件调用时,执行代码块 if __name__ == '__main__': print(randpass(8)) print(randpass(4))
时间模块
time 模块
时间表示方式
**时间戳 timestamp:**表示的是从 1970 年1月1日 00:00:00 开始按秒计算的偏移量
时间元组(struct_time): 由 9 个元素组成
结构化时间(struct_time)
使用 time.localtime() 等方法可以获得一个结构化时间元组。
>>> import time >>> time.localtime() time.struct_time(tm_year=2021, tm_mon=9, tm_mday=1, tm_hour=14, tm_min=23, tm_sec=29, tm_wday=2, tm_yday=244, tm_isdst=0)
结构化时间元组共有9个元素,按顺序排列如下表:
| 索引 | 属性 | 取值范围 |
|---|---|---|
| 0 | tm_year(年) | 比如 2021 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 59 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为-1 |
然结构化时间是一个元组,那么就可以通过索引进行取值,也可以进行分片,或者通过属性名获取对应的值。
>>> import time >>> t = time.localtime() >>> t time.struct_time(tm_year=2021, tm_mon=9, tm_mday=1, tm_hour=14, tm_min=23, tm_sec=29, tm_wday=2, tm_yday=244, tm_isdst=0) >>> t[3] 14 >>> t[1:3] (9, 1) >>> t.tm_mon 9
注意
但是要记住,Python的time类型是不可变类型,所有的时间值都只读,不能改
>>> t.tm_mon = 2 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: readonly attribute
格式化时间字符串
利用 time.strftime('%Y-%m-%d %H:%M:%S') 等方法可以获得一个格式化时间字符串
>>> import time
>>> time.strftime('%Y-%m-%d %H:%M:%S')
'2021-09-01 02:39:23'注意其中的空格、短横线和冒号都是美观修饰符号,真正起控制作用的是百分符
对于格式化控制字符串 "%Y-%m-%d %H:%M:%S,其中每一个字母所代表的意思如下表所示,注意大小写的区别:
| 格式 | 含义 | 格式 | 含义 |
|---|---|---|---|
| %a | 本地简化星期名称 | %m | 月份(01 - 12) |
| %A | 本地完整星期名称 | %M | 分钟数(00 - 59) |
| %b | 本地简化月份名称 | %p | 本地am或者pm的相应符 |
| %B | 本地完整月份名称 | %S | 秒(00 - 59) |
| %c | 本地相应的日期和时间 | %U | 一年中的星期数(00 – 53,星期日是一个星期的开始) |
| %d | 一个月中的第几天(01 - 31) | %w | 一个星期中的第几天(0 - 6,0是星期天) |
| %H | 一天中的第几个小时(24小时制,00 - 23) | %x | 本地相应日期 |
| %I | 第几个小时(12小时制,01 - 12) | %X | 本地相应时间 |
| %j | 一年中的第几天(001 - 366) | %y | 去掉世纪的年份(00 - 99) |
| %Z | 时区的名字 | %Y | 完整的年份 |
time 模块主要方法
1. time.sleep(t)
time 模块最常用的方法之一,用来睡眠或者暂停程序t秒,t可以是浮点数或整数。
2. time.time()
返回当前系统时间戳。时间戳可以做算术运算。
>>> time.time() 1630478727.255702
该方法经常用于计算程序运行时间:
import time def func(): time.sleep(1.14) pass t1 = time.time() func() t2 = time.time() print(t2 - t1) # print(t2 + 100) # print(t1 - 10) # print(t1*2)
3. time.localtime([secs])
将一个时间戳转换为 当前时区 的结构化时间。如果secs参数未提供,则以当前时间为准,即time.time()。
>>> time.localtime() time.struct_time(tm_year=2021, tm_mon=9, tm_mday=1, tm_hour=2, tm_min=47, tm_sec=29, tm_wday=2, tm_yday=244, tm_isdst=1) >>> time.localtime(1406391907) time.struct_time(tm_year=2014, tm_mon=7, tm_mday=26, tm_hour=12, tm_min=25, tm_sec=7, tm_wday=5, tm_yday=207, tm_isdst=1) >>> time.localtime(time.time() + 10000) time.struct_time(tm_year=2021, tm_mon=9, tm_mday=1, tm_hour=5, tm_min=35, tm_sec=1, tm_wday=2, tm_yday=244, tm_isdst=1) >>>
4. time.strftime(format [, t])
返回格式化字符串表示的当地时间。把一个struct_time(如time.localtime()和time.gmtime()的返回值)转化为格式化的时间字符串,显示的格式由参数format决定。如果未指定t,默认传入time.localtime()。
>>> time.strftime("%Y-%m-%d %H:%M:%S")
'2021-09-01 02:58:16'
>>> time.strftime("%Y-%m-%d %H:%M:%S", time.gmtime())
'2021-09-01 06:58:31'5. time.strptime(string[,format])
将格式化时间字符串转化成结构化时间
该方法是
time.strftime()方法的逆操作。time.strptime()方法根据指定的格式把一个时间字符串解析为时间元组。提供的字符串要和 format参数 的格式一一对应
如果string中日期间使用 “-” 分隔,format中也必须使用“-”分隔
时间中使用冒号 “:” 分隔,后面也必须使用冒号分隔
并且值也要在合法的区间范围内
>>> import time >>> stime = "2021-09-01 15:09:30" >>> st = time.strptime(stime,"%Y-%m-%d %H:%M:%S") >>> st time.struct_time(tm_year=2021, tm_mon=9, tm_mday=1, tm_hour=15, tm_min=9, tm_sec=30, tm_wday=2, tm_yday=244, tm_isdst=-1) >>> for item in st: ... print(item) ... 2021 9 1 15 9 30 2 244 -1 >>> wrong_time = "2021-14-26 12:11:30" >>> st = time.strptime(wrong_time,"%Y-%m-%d %H:%M:%S") Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/lib64/python3.6/_strptime.py", line 559, in _strptime_time tt = _strptime(data_string, format)[0] File "/usr/lib64/python3.6/_strptime.py", line 362, in _strptime (data_string, format)) ValueError: time data '2021-14-26 12:11:30' does not match format '%Y-%m-%d %H:%M:%S'a
练习 1:取出指定时间段的文本
需求
有一日志文件,按时间先后顺序记录日志
给定 时间范围,取出该范围内的日志
自定义日志文件 myweb.log
(mypy) [root@localhost day01]# vim myweb.log 2030-01-02 08:01:43 aaaaaaaaaaaaaaaaa 2030-01-02 08:34:23 bbbbbbbbbbbbbbbbbbbb 2030-01-02 09:23:12 ccccccccccccccccccccc 2030-01-02 10:56:13 ddddddddddddddddddddddddddd 2030-01-02 11:38:19 eeeeeeeeeeeeeeee 2030-01-02 12:02:28 ffffffffffffffff
【方案】
# 取出指定时间段 [9点~12点] 的行
from datetime import datetime # 导入datetime模块的datetime方法
# strptime(), 将字符时间'2030-01-02 09:00:00',转换成时间对象
t9 = datetime.strptime('2030-01-02 09:00:00', '%Y-%m-%d %H:%M:%S')
t12 = datetime.strptime('2030-01-02 12:00:00', '%Y-%m-%d %H:%M:%S')
# 读取日志文件myweb.log中的数据
with open('myweb.log') as fobj:
for line in fobj:
# strptime(), 将line[:19]截取的字符时间,转换成时间对象
t = datetime.strptime(line[:19], '%Y-%m-%d %H:%M:%S')
if t9 <= t <= t12: # 此种判断会遍历日志文件中的每一行,有可能执行大量无效操作,效率低下
print(line, end='')python 语法风格和模块布局
变量赋值
1. python支持链式多重赋值
>>> x = y = 10 # 将10赋值给x和y >>> x # 查看x的值 10 >>> y # 查看y的值 10 >>> y = 20 # 给变量y重新赋值为20 >>> y # 查看y的值 20 >>> x # x的值不发生变化 10
2. 给列表使用多重赋值时,两个列表同时指向同一个列表空间,任何一个列表改变,另外一个随着改变
>>> alist = blist = [1, 2] >>> alist # 查看列表alist的值 [1, 2] >>> blist # 查看列表blist的值 [1, 2] >>> blist[-1] = 100 # 修改列表blist中的最后一个元素为100 >>> alist # 当列表blist改变时,alist也会改变 [1, 100]
3. python 的多元赋值方法
>>> a, b = 10, 20 # 将10和20, 分别赋值给a和b >>> a # 查看变量a的值 10 >>> b # 查看变量a的值 20 >>> c, d = 'mn' # 将m和n, 分别赋值给c和d >>> c # 查看变量c的值 'm' >>> d # 查看变量d的值 'n' >>> e,f = (100, 200) # 将元组中的元素, 分别赋值给e和f >>> e # 查看变量e的值 100 >>> f # 查看变量f的值 200 >>> m, n = ['bob', 'alice'] # 将列表中的元素,分别赋值给变量m和变量n >>> m # 查看变量m的值 'bob' >>> n # 查看变量n的值 'alice'
4. 在python中,完成两个变量值的互换
>>> a, b = 100, 200 # 将100和200,分别赋值给变量a和变量b >>> a, b = b, a # 将变量a和变量b的值,进行交换 >>> a # 查看变量a的值 200 >>> b # 查看变量b的值 100
合法标识符
Python 标识符,字符串规则和其他大部分用 C 编写的高级语言相似
第一个字符必须是 字母或下划线 _
剩下的字符可以是字母和数字或下划线
大小写敏感
关键字
和其他的高级语言一样,python 也拥有一些被称作关键字的保留字符
任何语言的关键字应该保持相对的稳定,但是因为 python 是一门不断成长和进化的语言,其关键字偶尔会更新
关键字列表和 iskeyword() 函数都放入了 keyword 模块以便查阅
案例:查看,判断python中的关键字
>>> import keyword # 导入模块keyword
>>> keyword.kwlist # 查看keyword模块中,包含的关键字
>>> 'pass' in keyword.kwlist # 判断 'pass' 是否是python中的关键字,是
True
>>> keyword.iskeyword('abc') # 判断 'abc' 是否是python中的关键字,否
False内建
Python 为什么可以直接使用一些内建函数,而不用显式的导入它们?
比如 str()、int()、dir()、id()、type(),max(),min(),len() 等,许多许多非常好用,快捷方便的函数。
这些函数都是一个叫做
builtins模块中定义的函数,而builtins模块默认 在Python环境启动的时候就自动导入,所以可以直接使用这些函数
练习 2:测试字符串是否为合法标识符
需求
编写用于测试字符串的函数
函数用于确定字符串是否为合法标识符
字符串不能为关键字
import sys # 导入sys模块,用于传递位置参数 from string import ascii_letters,digits # 导入string模块的方法,获取大小写字母和数字的变量 import keyword # 导入keyword模块,用于判断是字符串是否是关键字 first_chs = ascii_letters + '_' # 变量的首字母必须是大小写字母或下划线 other_chs = first_chs + digits # 变量的其他字符必须是大小写字母,数字或下划线 def check_idt(idt): # 定义函数,判断字符是否合法,idt为形参 if keyword.iskeyword(idt): # 判断变量idt是否和关键字冲突 return '%s 是关键字' % idt # return执行时,会中断程序继续执行,返回结果 if idt[0] not in first_chs: # 判断变量idt的第一个字符是否是字母或下划线 return '第一个字符不合法' # return执行时,会中断程序继续执行,返回结果 for i in range(len(idt)): # 判断变量idt中,首字符以外的其他字符是否合法 if i == 0: # 变量idt的首字符已经判断,跳过即可 continue # 跳过本次循环 if idt[i] not in other_chs: # 判断idt首字符以外的其他字符是否合法 return '第%s个字符(%s)不合法' %(i+1, idt[i]) return '%s是合法的标识符' %idt # 测试代码块,__name__作为python文件调用时,执行代码块 if __name__ == '__main__': print(check_idt(sys.argv[1])) [root@localhost day04]# python check_idt.py for for 是关键字 [root@localhost day04]# python check_idt.py 2abc 2abc是合法的标识符 [root@localhost day04]# python check_idt.py abc@123 第4个字符(@)不合法 [root@localhost day04]# python check_idt.py abc_123 abc_123是合法的标识符
字符串
操作符
切片操作符:[ ]、[ : ]、[ : : ]
成员关系操作符:in、not in
格式化详解
可以使用格式化符号来表示特定含义
| 格式化字符 | 转换方式 |
|---|---|
| %s | 优先用str()函数进行字符串转换 |
| %d | 转成有符号十进制数 |
| %f | 转成浮点数 |
百分号
关于整数的输出
print("整数:%d,%d,%d" % (1, 22.22, 33))结果
整数:1,22,33
关于浮点数的输出
print("浮点数:%f,%f " % (1, 22.22))
print("浮点数保留两位小数:%.2f " % 22.222)结果
浮点数:1.000000,22.220000 浮点数保留两位小数:22.22
关于字符串的输出
print("字符串:%s,%s,%s" % (1, 22.22, [1, 2]))结果
字符串:1,22.22,[1, 2]
注意
可以传入任意类型的数据,如 整数、浮点数、列表、元组甚至字典,都会自动转成字符串类型
format 格式化输出
相对基本格式化输出采用 % 的方法,format() 功能更强大,该函数把字符串当成一个模板,通过传入的参数进行格式化,并且使用大括号 {} 作为特殊字符代替 %
位置匹配(最常用)
不带编号,即 “{}”
print("今天是{}的{}生日会".format("帅哥", 18))结果
今天是帅哥的18生日会
内建函数
# 删除 string 字符串两端的空白
>>> s4 = '\thello world '#定义变量s4, 左右两边有空白字符,\t 为制表符【这里显示为空白】
>>> print(s4)#打印s4,\t 制表符转换为空白字符
>>> s4.strip()#去掉变量s4,左右两边的空白字符
>>> s4.lstrip()#去掉变量s4,左边的空白字符,右边空白字符保留
>>> s4.rstrip()#去掉变量s4,右边的空白字符,左边空白字符保留
# 切割字符串,拼接字符串
>>> s2 = 'hello world'#定义一个字符串变量s2
>>> s3 = 'hello.tar.gz'#定义一个变量s3
>>> s2.split()#切割字符串s2, 存入列表中,默认以空格作为分隔符进行切割
>>> s3.split('.')#切割字符串s3, 存入列表中,这里以'.'作为分隔符进行切割
>>> alist = ['tom', 'bob', 'alice']#定义一个列表alist
>>> '_'.join(alist)#以'_'作为连接符,将列表alist中的元素拼接在一起
>>> ' '.join(alist)#以'.'作为连接符,将列表alist中的元素拼接在一起练习 5:创建用户
需求
编写一个程序,实现创建用户的功能
提示用户输入 用户名
随机生成 8位密码 (导入之前的模块文件)
创建用户并设置密码
将用户相关信息 写入指定文件
import randpass2 # 将randpass2.py作为模块调用
import subprocess # 调用subprocess模块,执行linux命令
import sys # 获取位置参数
# 定义函数adduser(), 创建用户,给用户设置密码,并保存用户信息到一个文件中
def adduser(user, passwd, fname):
# 使用run()执行linux命令,检查用户是否存在,存在打印已存在,return返回none,退出
result = subprocess.run('id %s &> /dev/null' % user, shell=True)
if result.returncode == 0:
print('%s已存在' % user)
return
# 用户不存在,使用run()创建用户,非交互式给用户设置密码
subprocess.run('useradd %s' % user, shell=True)
subprocess.run('echo %s | passwd --stdin %s' % (passwd, user), shell=True)
# 三引号,保留格式,用户记录用户的基本信息
info = """用户信息:
用户名:%s
密码:%s
""" % (user, passwd)
with open(fname, 'a') as fobj: # a 以追加的方式打开文件,写入用户信息
fobj.write(info)
if __name__ == '__main__':
passwd = randpass2.randpass() # 使用randpass2.py中的方法randpass(),生成一个8位的随机密码
adduser(sys.argv[1], passwd, '/tmp/users.txt') # sys.argv作为列表,保存用户的位置参数,argv[0]为文件名,所有从argv[1]开始测试
[root@localhost xxx]# python adduser.py tom /tmp/users.txt [root@localhost xxx]# python adduser.py tom /tmp/users.txt # 重新创建相同的用户时,提示已存在,正确







发表评论